

|
|
|
La minaccia fantasma
Privacy e sicurezza, rischi del 2006
Fin troppe volte, io come
altri, abbiamo parlato dell'insicurezza intrinseca nell'uso di Internet per i
trasferimenti di dati sensibili. Precauzioni, rischi o allergie derivate non
verranno trattati in questo documento. Qui si leggerà riguardo un problema
che può costituire una minaccia più pericolosa di una mail "intercettata":
Lo strapotere dei motori di ricerca
I dati personali sono
l'ambito premio che vuole ottenere chi attenta alla vostra privacy. Se
possedete un segreto esplicito, il vostro nemico/concorrente potrebbe agire per
impadronirsene. Questo è semplice da immaginare perché si tratta di uno scontro
tra due utenti informatici, un sistema vittima ed un attaccante.
Quando si parla di protezione si allude
ai propri dati, quelli che usiamo per lavoro, studio, ricerca... Comunicare un'e-mail che spiega le
nostre intenzioni ci può mettere a disagio, farci pensare a quanto sarebbe fastidioso se
perdessimo la segretezza che per ora vogliamo mantenere. Tuttavia il fatto di possederli non ci dà
alcun beneficio, è il loro utilizzo che ci può interessare.
Quindi, una volta compreso
questo semplice passo, diventa logico pensare che la sicurezza dei nostri dati
e la loro segretezza dipendano dalla sicurezza e dalla segretezza che il nostro
computer è in grado di mantenere.
I virus come sono
"conosciuti" non prendono i dati. Infettano i PC e non si capisce perché
vengano fatti. Questo non è più vero da almeno 4 anni. Se prima i "virus"
erano sviluppati per fare danni e propagarsi, ora sono pensati perché l'autore possa
interrogarli e dar loro dei comandi da eseguire, in modo da sfruttare i dati o la
potenza di calcolo sul computer della vittima. Ma anche i virus evolvono, ora i
nostri documenti sensibili possono essere inviati automaticamente in giro per
il mondo e lì con tranquillità analizzati.
Ok, presa consapevolezza, persi i propri dati
qualche volta, ipotizziamo di aver installato un antivirus, firewall, ecc...
Ci siamo protetti. Ora i nostri dati sono al sicuro?
No.
Come no?
No perché, normalmente, siamo proprio noi a comunicare a sconosciuti i nostri dati sensibili.
Pensate alla navigazione
in Internet di un utente. Forum, siti di informazione, motori di ricerca, webmail,
mailing list, newsgroup. In tutti questi luoghi virtuali spargiamo delle informazioni che ci riguardano.
Su "maporama" lasciamo indicazione di un luogo dove vogliamo recarci e del quale ci serve una mappa.
Sul forum chiediamo quale prodotto comprare, perché il vecchio non ci ha convinti.
Sul motore di ricerca cerchiamo informazioni riguardo a quello cui lavoriamo, per vedere se altri hanno già
fatto qualcosa di simile, ne hanno già discusso o se già esiste quello che vogliamo realizzare. Sicuramente
non cerchiamo informazioni che non ci interessano.
Se ci fosse un servizio
statale in grado di offrire e-mail veloci, forum gratuiti, motore di ricerca
internazionale, servizi di consultazione conti correnti... ci fideremmo?
Probabilmente di meno.
Si capirebbe troppo chiaramente che facendo affidamento ad un sito solo, questo sito saprebbe tutto
di noi.
Si capirebbe troppo chiaramente che, se perdessimo la nostra login e la password di un sito così
importante, un malintenzionato potrebbe sapere tutto di noi.
La percezione di "diffondere" informazioni, anche obiettivamente sensibili, sotto uno
pseudonimo scelto a caso, con altri pseudonimi più o meno conosciuti, ci dà la sensazione
di stare tra un gruppo di persone più o meno fidate, con le quali perlomeno possiamo parlare senza
filtri in un determinato contesto.
Ma cosa potrebbe succedere, se qualcuno,
o qualcosa, fosse in grado di mettere insieme tutti i pezzetti di informazioni che ci riguardano e che sparpagliamo per la rete?
Se quello che abbiamo scritto in una e-mail, i siti visitati l'altro ieri e l'annuncio su un blog fossero tutti riconducibili a noi?
Sarebbe un incubo?
"Hai mai fatto un sogno così
reale, da non capire se è un sogno o realtà?"
Ma non lo è. O almeno i
prerequisiti tecnici perché non sia solo un brutto incubo ci sono. Sta quindi alla buona fede
dell'entità non sfruttare questi dati contro di noi.
Chi e cos'è quest'entità?
Sono i motori di ricerca,
l'unico strumento su Internet davvero insostituibile. Insostituibile perché
svolge una funzione di "unione" tra il bisogno dell'utente di accedere ad un
archivio unico e centralizzato e la necessità della rete di essere
decentralizzata e sparsa.
Un motore di ricerca è unico e può essere visto come punto di congiunzione, come nesso in comune
attraverso cui tutta la rete di persone (noi e gli altri) passa per raggiungere Internet. Un punto di congiunzione che ci
dà la visibilità sulle informazioni, che sa cosa stiamo cercando, che sa cosa abbiamo cercato ieri e
conosce su cosa abbiamo cliccato ieri.
Ora c'è da mettere in chiaro
la mia posizione, mi sforzo di essere obiettivo, ma dopo anni di sicurezza informatica e difesa della
privacy, valuto le tecnologie in relazione al "caso peggiore".
Per questo non continuo raccontando quel che suppongo, ma esporrò quel che
tecnicamente è certo, le possibilità alle quali già ora viene lasciato spazio.
Quando si parla di "motori
di ricerca" inconsciamente si pensa a Google, Yahoo, Alltheweb e pochi altri.
L'analisi che segue verte per lo più su Google, tecnicamente il migliore secondo molti
aspetti, e di conseguenza anche il più inquietante.
1)
Il cookie "eterno": Google è l'unica entità che usa i
cookie impostati per spirare domenica 17 Gennaio del 2038, cioè la massima
data esprimibile attualmente con 32 bit. Se avessero potuto mettere 2100
l'avrebbero fatto, e perché? Basta pensare all'utilità di un cookie. Agli
albori del web, i cookie aiutavano ad ottimizzare la trasmissione. Quando mi
collegavo ad un sito scaricavo con il modem macinino a 56k tutte le pesanti immagini
e un piccolo cookie. La volta successiva la presenza di quel cookie nel mio
browser mi consentiva di sapere che non avrei dovuto riscaricare le immagini,
le avevo già nella cache. In seguito le vecchie e statiche pagine HTML sono
diventate dinamiche, si sono trasformate in applicazioni, è stato necessario
identificare gli utenti ed i cookie hanno preso la funzione di "riconoscere" un
utente che si era autenticato con una certa coppia username/password tempo prima, in
modo da togliergli la pesantezza di rifare login. I cookie attualmente, vista
la quantità di web application che usiamo, prendono significato per il server
consentendogli di lasciare informazioni sul nostro computer (lingua, identificativo univoco che gli
consente di farci autenticare senza login e password, date di accesso,
preferenze,...). È una feature a tutti gli effetti.
Ma
il cookie del quale parliamo esiste ben prima che venissero lanciati servizi
quali Gmail, Orkut, gli utenti Google per newsgroup e tutti gli altri strumenti
gentilmente offertici. E prima a che serviva? A che serviva un cookie con una durata così
PALESEMENTE INFINITA? L'unica utilità che mi spiego è quella di poterlo tenere
facilmente memorizzato in uno dei suoi infimi e lenti database, e poter
selezionare le ricerche che un cookie ha effettuato nei suoi mesi di attività.
Un cookie = un computer. Questa è paranoia? Viene fatto, attualmente, ora però
è sotto forma di servizio (prima solo una feature dietro le quinte)
Finchè
penso a yahoo, che sin dall'inizio offriva il servizio di webmail oltre che di
motore di ricerca, riesco a trovare un motivo al suo cookie. Ma nel caso di Google, famoso
per il suo minimalismo grafico, a cos'altro poteva servire un cookie che dal
1998 sarebbe durato QUARANT'ANNI?
Attualmente
quindi sappiamo che, senza compiere l'adeguata pulizia che non viene mai
effettuata come routine dagli utenti di medio e basso profilo tecnico
(praticamente: la grande massa), le ricerche effettuate su un computer possono
venire tracciate. Questo implica almeno due grossi problemi:
-
La profilazione
dell'utente: l'utente che usa il computer ha il suo cookie che consente ad un
motore di ricerca di mettere in ordine tutte le sue ricerche effettuate. Che
saranno mai? Semplicemente le nostre curiosità, passioni, conoscenze che
crescono con il tempo, lavori che seguiamo, persone che conosciamo, eventi ai
quali partecipiamo, il nostro nome in più di una salsa, ecc. Sì. Decisamente
sufficiente per essere preoccupati.
-
L'"immagine"
degli interessi della massa. La massa è il target per eccellenza, se vendo
lavatrici non cerco di conquistare la massaia 90enne che lava al fosso con il
sapone di marsiglia, perché rappresenta una minoranza. Ma tutte le famiglie, i single e
le massaie rimanenti, loro sono un target succulento per le mie lavatrici.
Supponi ora di sapere cosa le persone CERCANO, come resistere all'opportunità
di dar loro il suggerimento che si aspettano? Come poi resistere quando posso
rivendere questo servizio pubblicitario? Più di una mamma mi ha detto "preferisco
che mio figlio/a veda un film bollino rosso con me, che lasciarlo/a davanti
alla pubblicità di un pomeriggio". Capisco l'amore materno, ma che noi
possiamo essere vittime quanto gli altri non ci starà mica sfuggendo?
Quello
che un motore di ricerca può offrire è ancora meglio. La "profilazione", ovvero la tecnica con la
quale raccogliendo informazioni su una persona si può descrivere il suo profilo
comportamentale, di interessi e di cultura dà spazio ad attacchi ancora più
seducenti. Quando il nostro profilo è collegato al nostro cookie, quando la
nostra storia può essere presa a riferimento per il suggerimento adeguato,
otteniamo una pubblicità mirata su quello che ci interessa in un determinato
momento e contestualizzato per chi siamo. Pubblicità su misura per ogni utente,
esiste qualcosa più irresistibile?
Capisco
che nella mia analisi possa sembrare davvero negativo, ma se penso all'infinità di tecnologia a
disposizione di Google, alle ricerche di personale che effettuano, alle
capacità richieste ai loro collaboratori, mi chiedo quanti nonni ricchi deve
avere per finanziare un'opera così filantropica e pura, per di più: GRATIS!
2)
Quanto vale la prima posizione nella pagina dei risultati di una ricerca? In un motore di
ricerca, essa dovrebbe essere legata all'attinenza della fonte con l'argomento
cercato, valutata in relazione a quanti altri siti la usano come "riferimento".
Ci sono decine di algoritmi pensati per gestire il "ranking"
(la rilevanza associata ad un link in modo da assegnargli una posizione più alta
nella pagina dei risultati rispetto ad uno di rilevanza inferiore) nel modo più obiettivo
possibile.
In
un mondo perfetto infatti, il tasto "mi sento fortunato" che ti manda
automaticamente al primo link dei risultati, sarebbe davvero una soluzione magica: inserisci
una domanda e ti appare la risposta. In un mondo perfetto l'informazione
sarebbe corretta, obiettiva, imparziale, in modo da indottrinarci senza volerci
trasmettere una visione parziale dell'argomento di nostro interesse. Il mondo perfetto non
esiste, tutti siamo parziali e soggettivi. Anche i primi 5-6 link che appaiono in risposta
ad una ricerca. Ho detto 5-6 volutamente, perché "normalmente" non si aprono
più di 5 siti alla ricerca di una risposta, se non la si è trovata è molto più
facile affinare i criteri ed eseguire una nuova ricerca ottenendo per risultato altri siti.
Cosa
implica questo? Normalmente se leggiamo una descrizione che riguarda un argomento che conosciamo
sappiamo dire se essa è in linea con quello che sappiamo a riguardo. Meglio ancora sarebbe
possedere un'esperienza personale da usare come metro di paragone per valutare la bontà
dell'informazione che riceviamo, ma in mancanza di altro, conoscenze bilaterali possono già dare
una buona base. Quando invece apprendiamo qualcosa di nuovo, ci viene naturale credere all'informazione
ed acquisirla così com'è.
Tutti
siamo rimasti stupiti da quanto sia facile apprendere nuove informazioni con
Internet! Inserisci una domanda, una curiosità, la radice per un chiarimento e
lo trovi sempre! Ma ci siamo mai interrogati riguardo l'imparzialità dell'informazione ottenuta?
Sicuramente. La risposta sta nel sito che abbiamo visualizzato. Un'università,
un blog con commenti seri e sensati, un sito di un professionista. Ma la
risposta non deve stare in chi, genuinamente, mette a disposizione la propria
conoscenza, ma piuttosto nella domanda: "perché sto leggendo solo questo e non
consulto le altre fonti?"
Perché
siamo umani, pigri, vogliamo una risposta e il primo link verosimile ci basta.
Nulla da ridire su questo, anch'io leggo a malapena 2-3 link, infatti sono vittima
quanto voi altri dell'INFORMAZIONE GUIDATA.
Ora
bisogna vedere quanto, massivamente, le persone diano più importanza ai primi
link piuttosto che ai seguenti. Ho disegnato un grafico, è stato realizzato analizzando i dati
raccolti da un proxy di 600 utenti in una settimana (grazie ad un amico segreto di LK :).
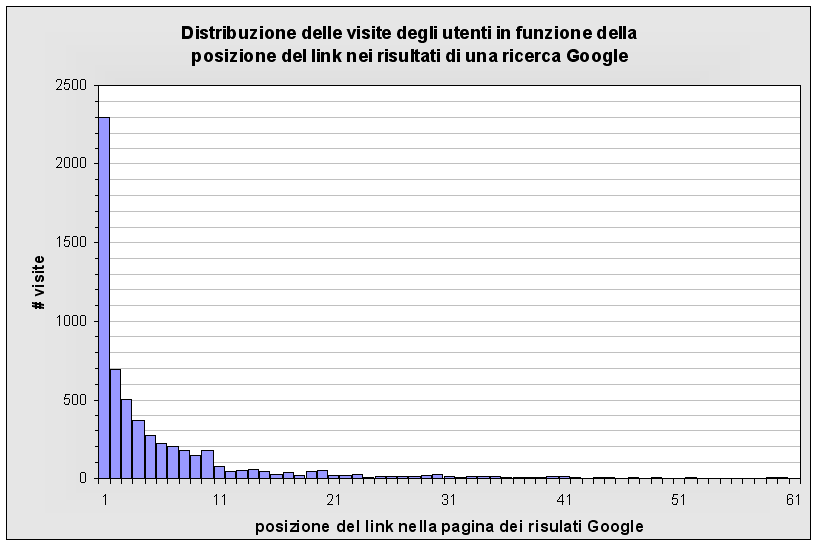
Come indicato, l'immagine mostra quanto un link che compare tra i risultati di una ricerca alla posizione più elevata
viene preferito a quelli in posizioni più basse. È naturale
che fosse ovvio, ma un divario tale tra i primi link ed i successivi non lo immaginavo.
L'analisi è stata fatta grazie alle chiamate a www.google.*/url?, ovvero la stessa base di dati che
Google usa per valutare il comportamento degli utenti.
Alla conferenza E-Privacy 2006 avevo pubblicato un
grafico raccolto in modo molto meno attendibile ed anche i risultati parevano meno preoccupanti.
L'informazione guidata è un
rischio elevato, anche perché un motore di ricerca può godere di tecniche e di approci del tutto nuovi ed
inattaccabili.
I sistemi di disinformazione attuali sono attaccabili e riconoscibili. Se
seguiamo un telegiornale che in modo evidente omette un certo tipo di notizia,
noi lo notiamo.
Se sappiamo che il professore di nostro figlio parla ai suoi alunni solo di un aspetto a lui caro, lo scopriamo. Ce ne accorgiamo perché
su una quantità finita di tempo (giorni, settimane) si nota obiettivamente la pressione informativa che "il telegiornale" o "il professore"
stanno esercitando. Questo è possibile grazie a due fattori:
-
Il tempo di
esposizione è limitato e contestualizzato, un telegiornale per i suoi 40
minuti, il professore per le sue ore settimanali, e sussiste la possibilità di
effettuare delle comparazioni tra telegiornali o professori differenti. Per un
motore di ricerca questo non è vero, l'esposizione è perenne, incomparabile e
trasparente. Perenne perché per tutti c'è sempre la possibilità di cercare come
di non cercare, diventando poco a poco sempre più un'abitudine se non una
necessità. Incomparabile perché non è dimostrabile in nessun modo che l'ordine
di uscita dei link sia o non sia stato controllato, a volte sono più
attendibili a volte meno, ma il valore del ranking è segreto e noto solo a
Google.
-
La trasparenza
della disinformazione. Quando navighiamo e cerchiamo ci fidiamo, più o meno,
della fonte informativa. A volte non si cercano informazioni per imparare, ma
semplicemente per confrontare, ricordare, rivedere. Raramente, questo accade in
ambiti dei quali abbiamo avuto esperienza in prima persona, e la percezione che abbiamo sviluppato
o che riteniamo sia obiettiva la ritroviamo inequivocabilmente distorta nelle informazioni ottenute dalla ricerca.
Questo di per sè è un limite dell'informazione: l'obiettività di chi la riporta. Entro la sfumatura consentita
nessuno noterà mai la differenza eccetto chi ha vissuto un'esperienza diretta, per cui quella porzione di verità la
si può considerare persa a priori. Un'ulteriore fetta di verità può essere
persa quando chi dovrebbe riportare l'informazione decide di interpretarla,
di prevedere il futuro, di omettere quello che non gli sembra logico, ecc.
Supponiamo di accorgercene, di rientrare in quella minuscola percentuale abbastanza
ferrata sull'argomento da capire che qualcosa non è corretto. Consideriamo la
fonte errata, premiamo il tasto "back" sul nostro browser, torniamo al motore
di ricerca catalogando la fonte come non fidata. Ciò nonostante, ci continuiamo
a fidare di chi ci ha proposto tale fonte! Il motore di ricerca è nel mezzo, da
licenza dice che lui non ha colpa nè merito dei contenuti che vengono
propinati, ciò nonostante ne ha il controllo quasi assoluto, dal momento che posizionare
un link 10 posti più in basso è sufficiente perché l'informazione venga ignorata
dalla massa.
-
L'inattaccabilità
della disinformazione. Gli algoritmi di ranking sono segreti, il ranking
dipende dal pagerank, il pagerank dipende dagli aggiornamenti quotidiani, dai
collaboratori Google, dai filtri, dalla cache di ricerca (come potrebbe
rispondere in un decimo di secondo dicendo che ha trovato 2 milioni di record
relativi alla keyword inserita?). Per cui, nessuno potrà mai dire: "Questo
output è del tutto arbitrario e parziale". Perché da licenza, da feature e da
comprensione umana, è naturale che le ricerche cambino in relazione alle
keyword inserite, alla lingua, all'ordine degli argomenti e quant'altro. E
anche quando la manipolazione dei risultati dovesse essere palese, lo stesso output non sarebbe
rigenerabile successivamente.
La
considerazione tuttavia più piccante non è questa. L'informazione guidata
intesa come manipolazione delle idee della massa è qualcosa da teoria
cospirativa davvero troppo forte. Non voglio intendere che per forza ci siano
motivazioni politiche o commerciali in grado di far cambiare il ranking di un
link piuttosto che un altro, anche perché la scalata di un link può essere in
qualche modo controllata dagli utenti stessi tramite sistemi collaborativi di
pubblicizzazione. Quello che più è plausibile e di entità altrettanto
fastidiosa è la censura delle informazioni. Google.cn non fa testo, quello
esplicitamente censura, ma in un contesto di informazione apparentemente libera
come quello di tutti gli altri stati democratici, la censura è vietata e soprattuto suscita
scalpore. Quando un libro, un film o un software viene censurato, la rilevanza
che prende è decisamente superiore a quella che aveva prima. Quindi perché
censurare esplicitamente ottenendo un effetto opposto a quello desiderato, quando si può censurare
implicitamente? Se un link che riporta a determinati contenuti avesse un
pagerank inspiegabilmente basso, si potrebbe incolpare qualcuno o qualcosa? Si
noterebbe?
3) Il raggio d'azione aumenta, gli ADS, le e-mail, le
mappe, il calendario, le news,...
Il
fatto di essere semplice indice ed archivio di Internet offriva delle possibilità ridotte.
Effettivamente i due fattori spiegati poco fa possono bastare per avere un controllo
limitato sui profili. È necessario sapere cosa veramente un utente faccia su un
sito, cosa segua e cosa gli interessi. C'è già stato un aggiornamento durante
gli anni. Se prima i motori di ricerca esplicitamente fornivano dei link sui
quali tu utente cliccavi (senza che essi potessero sapere cosa avevi scelto), ora no, ora
comunichi il link scelto al motore e poi lui ti redirige.
Apparentemente
questa notizia può sembrare falsa, chiunque di voi effettui una ricerca noterà che in
basso a sinistra, sulla barra del browser appare il link al sito che
contatteremo. Ma non è così, tramite una banale tecnica tipicamente usata per
gli attacchi di phishing si fa in modo che l'url che appare scritto e che
viene riportato in basso a sinistra sia differente da quello che verrà chiamato
veramente. Ok, ora sanno quali link ho scelto. Cos'altro?
Quando navigo su un sito che richiama gli ADS, il cookie Google viene passato, ed in relazione al tuo profilo,
correlato al sito che stai visitando, escono le adeguate informazioni pubblicitarie.
Quando
leggi un'e-mail, in relazione al tuo profilo ed al contenuto della lettera, gli ADS
vengono corredati su misura affinchè ti suggeriscano la risposta alle ipotetiche domande che
possano venirti in mente.
Quando
su Google Map inserisci un indirizzo, zoomi per vedere i dettagli della cartina, per
riconoscere la specifica piazza e la specifica colonna,... lo starai facendo di un
posto a caso o di un luogo in cui sei stato o dove intendi andare?
Diventa intuitivo capire che un portale al quale diamo i dati, alla peggio, potrà
mantenerli per effettuare analisi, rivenderli, studiarli. Avete mai notato quei
siti che mettono banner proponendoci di incontrare ragazze della nostra zona... e che ci indicano
con precisione la città in cui abitiamo!? Questo diventa possibile quando il raggio d'azione di un
portale aumenta. I dati correlati e studiati non sono più quelli di un solo portale, ma quelli
di molti. L'offerta di amiche sexy in relazione alla zona in cui viviamo è possibile grazie
all'informazione che abbiamo dato ad un sito di mappe online: tramite il cookie l'utente viene riconosciuto,
attraverso l'informazione che ha inserito (un punto di interesse, casa sua, ecc...) viene profilato
e per mezzo di un banner scritto ad hoc viene agganciato dal marketing.
Non è per forza un male avere un'offerta pubblicitaria piu' aderente alla propria persona,
tanto di pubblicità ne riceveremmo comunque, tantovale sia qualcosa di sensato. Il punto però
è che in questo modo il raggio di profilazione aumenta a dismisura. Volendo definire questo processo,
si può assumere che se un elemento che centralizza servizi (quindi accumula varie tipologie di dati)
amplia l'offerta dei suoi servizi, allora aumenta il numero di campi di azione su cui può eseguire correlazione.
Prima la mappa, poi l'e-mail, poi la ricerca, poi gli impegni sul calendario e così via.
Essendo una procedura che non avviene in modo visibile, comprensibile ed esplicito, l'effetto seduttivo
sull'acquirente è potentissimo. Il problema maggiore si verifica quando le informazioni ottenute dalle nostre ricerche CAMBIANO in relazione a chi siamo, a dove ci troviamo, a cosa normalmente piace a quelli come noi in modo tale che gruppi di utenti affini ricevano informazioni uniformi capaci di incanalarli in precisi schemi definiti da una terza parte.
Questi elementi, uniti,
protratti nel tempo, in uno storage virtualmente infinito rappresentano la cosa più simile
a quel "grande orecchio" che ascolta tutte le nostre connessioni. L'ipotetico
grande fratello di tutti i romanzi. Ma questo esiste, è reale.
Il motivo non è il controllo. Purtroppo no.
Davvero, l'obiettivo di
Google, e lo dico con quasi assoluta certezza, non è collaborare con un
governo liberticida aspettando che "V" for Vendetta ci liberi. Può essere una
pepita golosa per molti, certo. Può essere usato in limitati campi d'azione
(campi d'azione già protetti da altri sistemi di disinformazione potrebbero,
come extra, sfruttare Google). Verosimilmente un colosso come Google non potrebbe
mai prendere esplicitamente parte a cospirazioni censorie e mantenere la cosa segreta.
Casi diplomatici come Google.cn non sono un esempio valido. Ma basti pensare alla quantità
di personale che vi lavora sopra, un'informazione di tale delicatezza trapelerebbe decuplicando
la visibilità dell'oggetto censurato. Mentre è meno segreto che il potere di google è LA
PUBBLICITÀ.
La stessa seducente,
simpatica ed innocente pappardella del bambino felice con il kinder sorpresa,
della gnocca che ti slingua se mangi lo yogurt. La televisione è stata uno dei
sistemi a tramissione monodirezionale più forti. Una pressione psicologica
esercitata per anni, in cui il più potente decideva cosa sarebbe stato venduto.
Internet pareva più libera, ed in effetti lo è. Qui il miglior offerente di un
settore riesce a prendersi i posti migliori. E qui entra in gioco la
profilazione. Se prima si poteva presupporre, nonostante
l'antitrust, che un colosso fosse in grado di controllare il mercato del proprio settore, ora
non è più così. Certo, se cercherai "router" Cisco sarà
sempre presente in 9 risultati su 10, ma più specifiche saranno le parole chiave inserite più
troverai qualcosa di adeguato alla tua ricerca. Questa è la profilazione: sapere cosa vuoi e proporti il
link di chi ha pagato per apparire sul tuo monitor in quel preciso momento.
La profilazione cresce, si
perfeziona, si avvicina a te, conoscendoti in aspetti che tu stesso ignori.
Questo è il rischio: che ti vengano propinati prodotti, idee, concetti, nel
modo per cui sei più vulnerabile.
Le considerazioni piccanti
vengono analizzando il fenomeno degli spyware. Anni fa non esistevano,
l'interesse del programmatore era di diffondere la propria opera, ma di essere
pagato. Per suscitare interesse nell'utente, lo sviluppatore doveva far provare per un
po' il suo programma, tipicamente 30 giorni di prova: licenza shareware.
Dopo un po' cessò di essere
importante che l'utente pagasse l'applicazione, essa sarebbe stata gratuita... Dopo
la prima ondata di informatici usciti dalla scuola, qualche programmatore valido
alle prime esperienze non sarebbe stato difficile da trovare.
Quindi cosa si poteva chiedere all'utente? Le sue preferenze.
Chi se ne frega delle preferenze dell'utente? Ogni persona che ritiene di "non aver nulla da
nascondere", o che pensa "quale hacker verrebbe mai ad attaccare proprio me?" mentre
apre un attachment di "I LOVE YOU" vedendo che un software nella licenza gli chiedeva
di sbirciare il suo comportamento avrebbe accettato di buon grado. E così è
stato, forse Gator ha rappresentato uno dei primi software con questa licenza,
sicuramente il più invasivo. E così la licenza spyware a poco a poco è diventata
così invasiva da diventare un malware.
Al tempo la licenza spyware veniva sottoscritta ed accettata per ignoranza, inconsapevolezza (non si era
ancora subito lo spamming come lo conosciamo ora), ma soprattutto perché essendo una licenza
del tutto legittima, veniva ignorata come la maggior parte delle licenze.
Guarda caso, quando si sottoscrive qualche servizio Google si accetta una delle tante licenze liquidate
con un "accetto e proseguo".
In quella licenze non si dice "tutto e nulla" come si teme. Dicono apertamente che Google
analizza i dati raccolti a fini statistici. Ma i dati raccolti non sono solo "le 10 parole più ricercate
nel mondo", sono i nostri cookie, i nostri referrer, le ricerche ad essi correlate, ecc.
Che Google sia il primo spyware al quale "ci si affida" in cambio di un servizio? È la stessa
cosa del software in demo degli anni 1998-2000.
Ma supponiamo questo articolo venga letto da molte persone, diciamo quelle che leggono PuntoInformatico,
quelle che seguono mailing list tecniche e dagli amici di queste persone. Cosa cambia? Nulla. Nulla perché
uno strumento simile ha come finalità l'attacco alle MASSE. Anzi, sono una porzione di informazioni
che seguono condizioni ferree, alle quali non possiamo sottrarci.
Singolamente possiamo proteggerci, ma ci sono informazioni che prendono valore in relazione al numero di persone
che le stanno richiedendo, e la maggior parte degli utenti non usa alcuna protezione a riguardo. A quel punto, che ci
si sia protetti o meno, le azioni intraprese saranno le stesse nei confronti della massa, noi compresi.
Paragrafo molto pesante.
È tardi per sottolineare che NON vedo Google, Yahoo, Alltheweb come
"Il Male Assoluto"? Sono un grande utilizzatore di motori di ricerca, apprezzo ogni singolo aspetto
della loro semplicità e delle caratteristiche che ti permettono di rendere più veloce la loro
funzionalità. Ad esempio uso Google Suggest, una versione beta che, tramite AJAX, legge la query di ricerca
e ti anticipa, suggerendoti come terminare la parola ed il suo numero di occorrenze. Ciò
nonostante la centralizzazione delle informazioni può costituire un enorme problema. Il motivo
per cui scrivo questo documento è legato alla natura del problema stesso, subdola, invisibile e tacita.
Il vantaggio di una rete è la distribuzione dei contenuti, ad esempio, su Youtube la settimana scorsa
un ragazzo ha messo un filmato amatoriale in cui suonava la chitarra. Grazie alla sua bravura il filmato ha
avuto un picco di visitatori evidente, la notizia è stata ripresa ed ora il ragazzo ha la
fama che si merita. Senza una risorsa come Internet sarebbe dovuto passare in mezzo a
lobby discografiche e chissà quali altri giri. L'informazione spicciola d'attualità subisce
le stesse difficoltà in un ambiente dove solo poche fonti nazionali note sono considerate autorevoli,
ma la possiblità di vedere sul blog dell'ultimo contadino cinese cosa accade realmente c'è
solo grazie alla decentralizzazione dell'informazione. Internet ci offre questo, il
motore di ricerca è una risorsa accessoria, senza di esso abbiamo solo più difficoltà a trovare ciò che ci interessa,
ma non per questo dobbiamo affidarci esclusivamente a lui. Dovremmo considerare significative le raccomandazioni e lo scambio di informazioni
tra persone molto di più dell'output di un motore di ricerca. La natura del problema è
atipica, si tratta dell'unione tra la necessità umana di avere informazioni,
l'enorme possibilità selvaggia e caotica di reperire dati sparsi per Internet
e degli algoritmi di mezzo che possono influenzare la conoscenza di chi si
affida ad essi. Svariate tecnologie hanno
provato ad affrontare il problema in modo diverso, per lo più sistemi a raccomandazione e sistemi
a filtro collaborativo. Si trova on-line della documentazione in inglese, cercando "collaborative filtering"
e "recommendation system". Cercando un primo approccio risolutivo,
spesso si immagina che un motore di ricerca possa fare i propri interessi, e come
risposta logica si propone l'utilizzo simultaneo di più motori di ricerca. Questa soluzione è attuabile
anche personalmente e non richiede l'ausilo di tecnologie particolari. La difficoltà maggiore
nelle meta-ricerche sta nel dover analizzare le pagine web ricevute come risposta
dai motori di ricerca, che possono cambiare quotidianamente ed inserire meccanismi di
protezione da questo genere di utilizzo congiunto. http://del.icio.us
è un tentativo di collaborative filtering e user ratings, ma il problema della
disinformazione non sta in chi può usare un software apposito, sta in tutti gli
altri. Analogamente alla crittografia, l'anonimato, il problema della difesa della privacy e quelli
derivanti dalla perdita della privacy, i rischi della disinformazione non sono pericolosi
per la percentuale minima di persone che sanno difendersi da essi, ma per la grande percentuale di utenti che
non sa farlo. In vista di uno studio
migliore a riguardo, nella speranza di aver dato qualche idea differente ad un
lettore su cento, ringrazio dell'attenzione.
Riferimenti/link (prometto di espanderli)
Progetto Winston Smith
http://www.winstonsmith.info
e la conferenza annuale
E-Privacy
Collaborative Filtering
e
Recommendation system
Google Watch
e questo link comico, ma
indicativo...
L'autore non ne sa nulla: ha scritto questo documento mentre era posseduto da www.20q.net (cioè Satana) [Marzo 2004 - Settembre 2006] ...avessi tempo...
vecna@s0ftpj.org
Pesante perché non sono
convinto la cosa possa essere percepita come un problema, ed anche una volta
identificato ed isolato non sono certo esista una soluzione definitiva che non costituisca un
semplice palliativo.
Il problema maggiore è:
"quanto interessa?" Io l'avverto, ma mediamente questo problema non si
porrebbe mai. Del resto la pubblicità ha segnato tre o quattro generazioni
senza che nessuno battesse ciglio, il fatto che si sia evoluta è un problema?
Questa volta, forse, è
diverso perché Internet è la prima tecnologia "aperta" su scala mondiale.
Televisione e telefono, per limiti tecnologici e per conformazione del network,
non potevano consentire lo stesso controllo del mezzo e della rete, Internet è
atipico per questo, per lo più.
Questa volta possiamo
valutare una soluzione, ma a chi interessa? A chi, consapevole del problema,
può selezionare ad occhio e manualmente i suoi criteri di scelta e dare alle cose
il giusto peso, o a chi, inconspevole, in ogni caso si fiderebbe della cosa più
immediata che gli appare davanti agli occhi?
Questa domanda non deve far pensare a due differenti caste di esseri umani, tutti ne
manifestiamo entrambi i comportamenti caratteristici, dipende solo dal campo d'azione. Se iniziassi
ad interessarmi di "ginnastica artistica"
non avendo inizialmente la minima visione critica e consapevole del tema crederei alle prime
informazioni ricevute, e per quanto mi sforzassi di non dar loro peso, quando penserò
alla "ginnastica artistica" le informazioni acquisite saranno pronte a tornare in superfice
nella mia mente.
Per cui, per quanto l'uso di una ricerca
obiettiva sia appetibile per tutti, la forma di diffusione di questo strumento
dovrebbe essere preferibile alla modalità offerta da Google/Yahoo/Alltheweb ed agli anni di
studi che stanno alle sue spalle. Una sfida abbastanza dura da vincere...
Per collaborative filtering si intendono degli strumenti in grado di fare una predizione di scelte
ed interessi segnalati dagli utenti. Il peso di un link può variare per la singola persona, per la
quantità di utenti che hanno richiesto le stesse cose, per l'importanza che sta
prendendo rispetto agli altri. Google in parte utilizza questo metodo per rivedere il
pagerank, la scelta degli ADS da pubblicare al singolo utente. Tuttavia la tecnologia di
filtro collaborativo può essere usata anche in ambienti distribuiti, per cui si può essere certi
della bontà degli algoritmi applicati e di una rete paritetica alla base delle selezioni e della loro imparzialità.
Un problema teorico sta nell'inquinamento della base di dati, come il pagerank di Google può essere inquinato,
un sistema paritetico anonimo soffre della stessa debolezza.
Per recommendation system si intendono sistemi in grado di far pervenire delle raccomandazioni,
vengono fatte tra utenti specifici e informaticamente può descrivere il passaparola che
contraddistigune la diffusione di una notizia.
L'unione di queste tecnologie, appoggiate ad una quantità enorme di dati (gli archivi della
maggior parte dei motori di ricerca) può soddisfare l'esigenza dell'utente di non effettuare
ricerche estenuanti e può garantire un'indipendenza informativa maggiore.
Inoltre, nonostante un'applicazione simile gestirebbe una vitalità infima per ogni cookie,
saremmo comunque tenuti ad accettare il rating scelto dai motori ai quali ci affidiamo, e per quanto
in questo caso all'utente sarebbe presentato un rating medio, il risultato rimarrebbe influenzato.
L'utilizzo di motori di ricerca fidati, intermedi, che effettuano delle meta ricerche è da escludersi,
sia perché la fiducia dovrebbe essere delegata al gestore e non ad una tecnologia verificabile,
sia perché possono essere bloccati da parte dei motori di ricerca gli accessi da parte di
sistemi che sfruttano la loro base dati, faticosamente acquisita.

Questo documento č pubblicato sotto una
Licenza Creative Commons.
Ringraziamento speciale a Damiano, il debugger ortografico